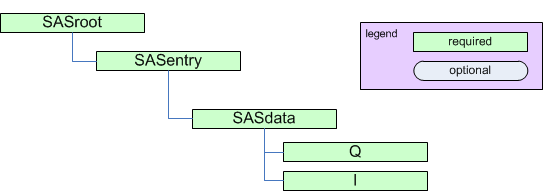
The minimum requirements for reduced small-angle scattering data
as described by canSAS are summarized in the following figure:
The minimum requirements for reduced small-angle scattering data.
(fullimage)
See below for the minimum required
information for a NeXus data file
written to the NXcanSAS specification.¶
Implementation of canSAS standard in NeXus
This application definition is an implementation of the canSAS
standard for storing both one-dimensional and multi-dimensional
reduced small-angle scattering data.
NXcanSAS is for reduced SAS data and metadata to be stored together in one file.
Reduced SAS data consists of \(I(\vec{Q})\) or \(I(|\vec{Q}|)\)
External file links are not to be used for the reduced data.
A good practice/practise is, at least, to include a reference to how the data was acquired and processed. Yet this is not a requirement.
There is no need for NXcanSAS to refer to any raw data.
The canSAS data format has a structure similar to NeXus, not identical.
To allow canSAS data to be expressed in NeXus, yet identifiable
by the canSAS standard, an additional group attribute canSAS_class
was introduced. Here is the mapping of some common groups.
group (*)
NX_class
canSAS_class
sasentry
NXentry
SASentry
sasdata
NXdata
SASdata
sasdetector
NXdetector
SASdetector
sasinstrument
NXinstrument
SASinstrument
sasnote
NXnote
SASnote
sasprocess
NXprocess
SASprocess
sasprocessnote
NXcollection
SASprocessnote
sastransmission
NXdata
SAStransmission_spectrum
sassample
NXsample
SASsample
sassource
NXsource
SASsource
(*) The name of each group is a suggestion,
not a fixed requirement and is chosen as fits each data file.
See the section on defining
NXDL group and field names.
Refer to the NeXus Coordinate System drawing (The NeXus Coordinate System)
for choice and direction of \(x\), \(y\), and \(z\) axes.
The minimum required information for a NeXus data file
written to the NXcanSAS specification.
1NXcanSAS HDF5 data file
2 entry : NXentry
3 @NX_class = "NXentry"
4 @canSAS_class = "SASentry"
5 @version = "1.0"
6 definition = "NXcanSAS"
7 run = "<see the documentation>"
8 title = "something descriptive yet short"
9 data : NXdata
10 @NX_class = "NXdata"
11 @canSAS_class = "SASdata"
12 @signal = "I"
13 @I_axes = "<see the documentation>"
14 @Q_indices : NX_INT = <see the documentation>
15 I : NX_NUMBER
16 @units = <see the documentation>
17 Q : NX_NUMBER
18 @units = NX_PER_LENGTH
Place the canSAS SASentry group as a child of a NeXus NXentry group
(when data from multiple techniques are being stored)
or as a replacement for the NXentry group.
Note: It is required for all numerical objects to provide
a units attribute that describes the engineering units.
Use the Unidata UDunits [1] specification
as this is compatible with various community standards.
Declares which NXdata group
contains the data to be shown by default.
It is needed to resolve ambiguity when more than one NXdata group exists.
The value is the name of the default NXdata group.
Usually, this will be the name of the first SASdata group.
Title of this SASentry.
Make it so that you can recognize the data by its title.
Could be the name of the sample,
the name for the measured data, or something else representative.
Run identification for this SASentry.
For many facilities, this is an integer, such as en experiment number.
Use multiple instances of run as needed, keeping
in mind that HDF5 requires unique names for all entities
in a group.
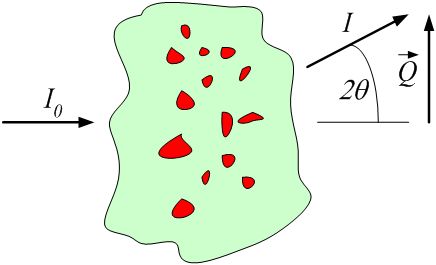
A SASData group contains a single reduced small-angle scattering data set
that can be represented as \(I(\vec{Q})\) or \(I(|\vec{Q}|)\).
Q can be either a vector (\(\vec{Q}\)) or a vector magnitude (\(|\vec{Q}|\))
The name of each SASdata group must be unique within a SASentry group.
Suggest using names such as sasdata01.
NOTE: For the first SASdata group, be sure to write the chosen name
into the SASentry/@default attribute, as in:
SASentry/@default="sasdata01"
A SASdata group has several attributes:
I_axes
Q_indices
Mask_indices
To indicate the dependency relationships of other varied parameters,
use attributes similar to @Mask_indices (such as @Temperature_indices
or @Pressure_indices).
String array that defines the independent data fields used in
the default plot for all of the dimensions of the signal field
(the signal field is the field in this group that is named by
the signal attribute of this group).
One entry is provided for every dimension of the I data object.
Such as:
@I_axes="Temperature","Time","Pressure","Q","Q"
Since there are five items in the list, the intensity field of this example
I must be a five-dimensional array (rank=5).
Integer or integer array that describes which indices
(of the \(I\) data object) are used to
reference the Q data object. The items in this array
use zero-based indexing. Such as:
@Q_indices=1,3,4
which indicates that Q requires three indices
from the \(I\) data object: one for time and
two for Q position. Thus, in this example, the
Q data is time-dependent: \(\vec{Q}(t)\).
The data mask must have the same shape as the data field.
Positions in the mask correspond to positions in the data field.
The value of the mask field may be either a boolean array
where false means no mask and true means mask
or a more descriptive array as as defined in NXdetector.
Integer or integer array that describes which indices
(of the \(I\) data object) are used to
reference the Mask data object. The items in this
array use zero-based indexing. Such as:
@Mask_indices=3,4
which indicates that Q requires two indices
from the \(I\) data object for Q position.
Names the dataset (in this SASdata group) that provides the
uncertainty to be used for data analysis.
The name of the dataset containing the \(Q\) uncertainty
is flexible. The name must be unique in the SASdata group.
Such as:
@uncertainties="Q_uncertainties"
The uncertainties field will have the same shape (dimensions)
as the Q field.
These values are the estimates of uncertainty of each Q. By default,
this will be interpreted to be the estimated standard deviation.
In special cases, when a standard deviation cannot possibly be used,
its value can specify another measure of distribution width.
There may also be a subdirectory (optional) with constituent
components.
Note
To report distribution in reported \(Q\) values,
use the @resolutions attribute. It is possible for both
@resolutions and uncertainties to be reported.
Names the dataset (in this SASdata group) containing the \(Q\) resolution.
The name of the dataset containing the \(Q\) resolution
is flexible. The name must be unique in the SASdata group.
The resolutions field will have the same shape (dimensions)
as the Q field.
Generally, this is the principal resolution of each \(Q\).
Names the data object (in this SASdata group) that provides the
\(Q\) resolution to be used for data analysis. Such as:
@resolutions="Qdev"
To specify two-dimensional resolution for slit-smearing geometry,
such as (dQw, dQl), use a string array, such as:
@resolutions="dQw","dQl"
There may also be a subdirectory (optional) with constituent
components.
This pattern will demonstrate how to introduce further as-yet
unanticipated terms related to the data.
By default, the values of the resolutions data object are assumed to be
one standard deviation of any function used to approximate the
resolution function. This equates to the width of the gaussian
distribution if a Gaussian is chosen. See the @resolutions_description
attribute.
Note
To report uncertainty in reported \(Q\) values,
use the @uncertainties attribute. It is possible for both
@resolutions and uncertainties to be reported.
(optional)
Generally, this describes the \(Q\)@resolutions data object.
By default, the value is assumed to be “Gaussian”. These are
suggestions:
Gaussian
Lorentzian
Square :
note that the full width of the square would be ~2.9 times
the standard deviation specified in the vector
Triangular
Sawtooth-outward : vertical edge pointing to larger Q
Sawtooth-inward vertical edge pointing to smaller Q
Bin : range of values contributing
(for example, when 2-D detector data have been reduced
to a 1-D \(I(|Q|)\) dataset)
For other meanings, it may be necessary to provide further details
such as the function used to assess the resolution.
In such cases, use additional datasets or a NXnote subgroup
to include that detail.
The intensity may be represented in one of these forms:
absolute units: \(d\Sigma/d\Omega(Q)\)
differential cross-section
per unit volume per unit solid angle (such as: 1/cm/sr or 1/m/sr)
absolute units: \(d\sigma/d\Omega(Q)\)
differential cross-section
per unit atom per unit solid angle (such as: cm^2 or m^2)
arbitrary units: \(I(Q)\)
usually a ratio of two detectors
but units are meaningless (such as: a.u. or counts)
This presents a few problems
for analysis software to sort out when reading the data.
Fortunately, it is possible to analyze the units to determine which type of
intensity is being reported and make choices at the time the file is read. But this is
an area for consideration and possible improvement.
One problem arises with software that automatically converts data into some canonical
units used by that software. The software should not convert units between these different
types of intensity indiscriminately.
A second problem is that when arbitrary units are used, then the set of possible
analytical results is restricted. With such units, no meaningful volume fraction
or number density can be determined directly from \(I(Q)\).
In some cases, it is possible to apply a factor to convert the arbitrary
units to an absolute scale. This should be considered as a possibility
of the analysis process.
Where this documentation says typical units, it is possible that small-angle
data may be presented in other units and still be consistent with NeXus.
See the NeXus Data Units section.
Names the dataset (in this SASdata group) that provides the
uncertainty of \(I\) to be used for data analysis.
The name of the dataset containing the \(I\) uncertainty
is flexible. The name must be unique in the SASdata group.
Generally, this is the estimate of the uncertainty of each \(I\).
Typically the estimated standard deviation.
Idev is the canonical name from the 1D standard.
The NXcanSAS standard allows for the name to be described using this attribute.
Such as:
(optional)
Names the field (a.k.a. dataset) that contains a factor
to multiply I. By default, this value is unity.
Should an uncertainty be associated with the scaling factor
field, the field containing that uncertainty would be
designated via the uncertainties attribute.
Such as:
The exact names for I_scaling and I_scaling_dev are not
defined by NXcanSAS. The user has the flexibility to use names
different than those shown in this example.
Engineering units to use when expressing
\(I\) and intensity-related terms.
Data expressed in other units (or missing a @units attribute)
will generate a warning from any validation process
and will be treated as arbitrary by some analysis software packages.
For software using the UDUNITS-2 library, arbitrary will be
changed to unknown for handling with that library.
\(Q\)resolution along the axis of scanning
(the high-resolution slit width direction).
Useful for defining resolution data from
slit-smearing instruments such as Bonse-Hart geometry.
Must have the same units as \(Q\).
When present, the name of this field is also
recorded in the resolutions attribute of Q,
as in:
\(Q\)resolution perpendicular to the axis of scanning
(the low-resolution slit length direction).
Useful for defining resolution data from
slit-smearing instruments such as Bonse-Hart geometry.
Must have the same units as \(Q\).
When present, the name of this field is also
recorded in the resolutions attribute of Q,
as in:
Description of the small-angle scattering instrument.
Consider, carefully, the relevance to the SAS data analysis process
when adding subgroups in this NXinstrument group. Additional information
can be added but will likely be ignored by standardized data anlysis processes.
The NeXus NXbeam base class may be added as a subgroup of this NXinstrument
group or as a subgroup of the NXsample group to describe properties of the beam at any
point downstream from the source.
Note: In NXdetector, the distance field records the
distance to the previous component … most often the sample.
This use is the same as SDD for most SAS
instruments but not all. For example, Bonse-Hart cameras
have one or more crystals between the sample and detector.
We define here the field SDD to document without
ambiguity the distance between sample and detector.
This is the x position where the direct beam would hit the detector plane.
This is a length and can be outside of the actual
detector. The length can be in physical units or pixels
as documented by the units attribute. The value can be any
real number (positive, zero, or negative).
This is the y position where the direct beam would hit the detector plane.
This is a length and can be outside of the actual
detector. The length can be in physical units or pixels
as documented by the units attribute. The value can be any
real number (positive, zero, or negative).
Transmission (\(I/I_0\)) of this sample.
There is no units attribute as this number is dimensionless.
Note: the ability to store a transmission spectrum,
instead of a single value, is provided elsewhere in the structure,
in the SAStransmission_spectrum element.
Add additional fields as needed to describe value(s) of any
variable, parameter, or term related to the SASprocess step.
Be sure to include units attributes for all numerical fields.
Names the dataset (in this SASdata group) that provides the
uncertainty of each transmission \(T\) to be used for data analysis.
The name of the dataset containing the \(T\) uncertainty
is expected to be Tdev.
{kind=link}
{kind=link}